Linux网络子系统性能观测研究报告
网络子系统性能观测研究报告
1.概述
随着智能网联汽车的发展,对车辆内、外通信的需求越来越高,也推动汽车网络技术的发展。车内应用进行网络通信,离不开内核的网络协议栈以及相应驱动程序的支持,所以观测网络性能, 就需要从内核中提取相关数据进行分析处理。
2.网络子系统背景介绍
2.1 协议栈
Linux内核网络协议栈由多种协议分层组成,如图1所示, 协议栈中每一层都有自己的职责。例如,IP协议允许通过多个路由器和网络发送数据报,可以重新组合数据包,但不能保证某些数据丢失时的可靠性,这需要在更高一层的如TCP协议中实现。
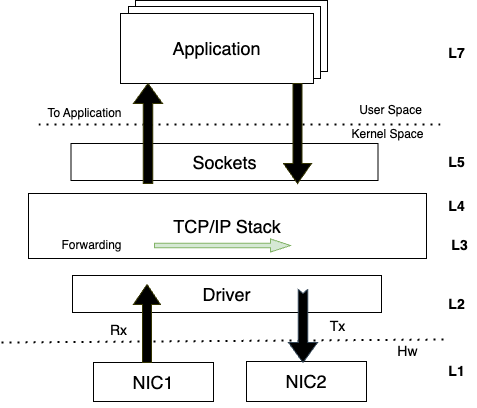
用户态应用程序通过socket接口与内核网络协议栈进行交互,协议栈又通过网卡驱动程序与网卡硬件进行交互,从而实现网络通信。
2.2 关键数据结构
纵观整个网络子系统,有几个关键的数据结构贯彻其中,如sk_buff、net_device、socket、sock等,他们之间的关系如图2所示。
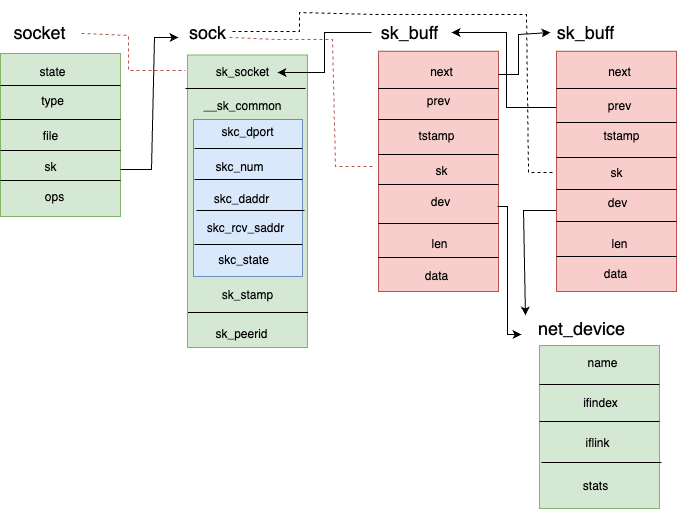
2.2.1 struct sk_buff
所有网络分层都会使用sk_buff结构来储存其报头、有关用户数据的信息,以及协调其工作的其他内部信息。从第二层到第四层都会使用这个数据结构。
内核使用一个双向链表来维护sk_buff结构,next指针指向下一个sk_buff结构,如图3所示。
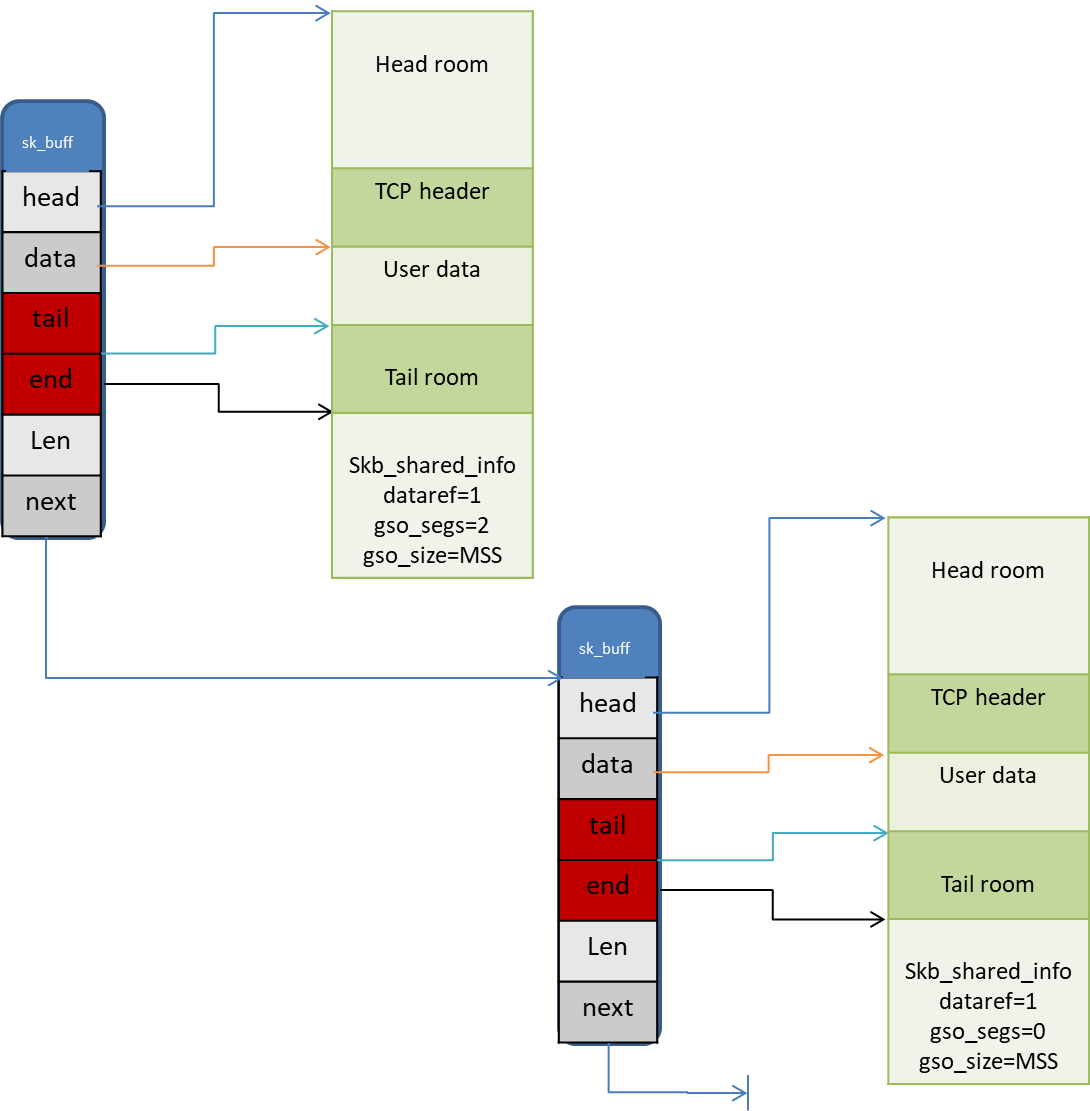
sk_buff结构体中重要字段描述:
| 字段 | 描述 |
|---|---|
| head | The start of the packet |
| data | The start of the packet payload |
| tail | The end of the packet payload |
| end | The end of the packet |
| len | The amount of data of the packet |
指针指向区域描述:
| 区域名称 | 描述 |
|---|---|
| head room | 位于head至data之间的空间,用于存储protocol header,如:TCP header, IP header, Ethernet header .etc |
| user data | 位于data至tail之间的空间,用于存储应用层数据,一般系统调用时会使用到。 |
| tail room | 位于tail至end之间的空间,用于填充用户数据未使用完的空间。 |
| skb_shared_info | 位于end之后,用于存储特殊数据结构skb_shared_info,该结构用于描述分片信息。 |
2.2.2 struct net_device
在内核中,网络设备被抽象为struct net_device结构,它是网络设备硬件与上层协议之间联系的接口,该结构包括网卡硬件类信息、统计类信息、上层协议处理接口、流控接口等。
1 | |
2.2.3 struct sock
内核中网络相关的很多函数,参数往往都是struct sock,函数内部依照不同的逻辑,将struct sock转换为不同的结构。struct sock *sk是贯穿并连接于L2~L5各层之间的纽带,也是网络中最核心的结构体。
1 | |
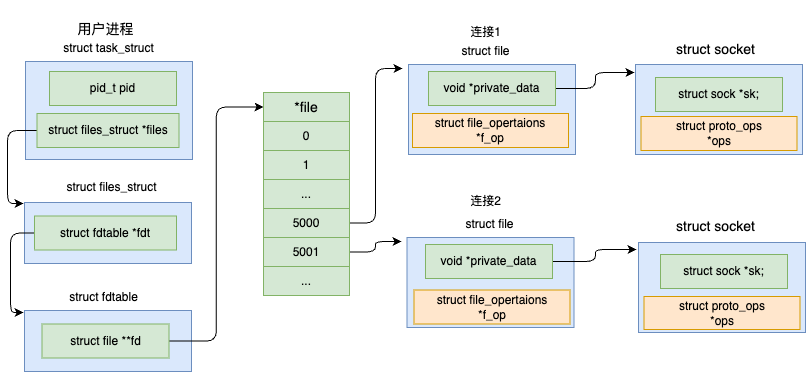
2.2.4 struct socket
内核中的进程通过文件描述符fd中的struct socket结构体与内核网络协议栈进行沟通,如图4所示。
1 | |
2.3 内核收包过程
收包过程大致可分为网卡初始化、网卡收包、DMA将包复制到RX队列、触发硬件中断IRQ、内核调度到ksoftirqd线程、软中断处理从ringbuffer取数据送到协议栈、协议栈L2处理、协议栈L3处理、协议栈L4处理这9个过程,如图5所示。
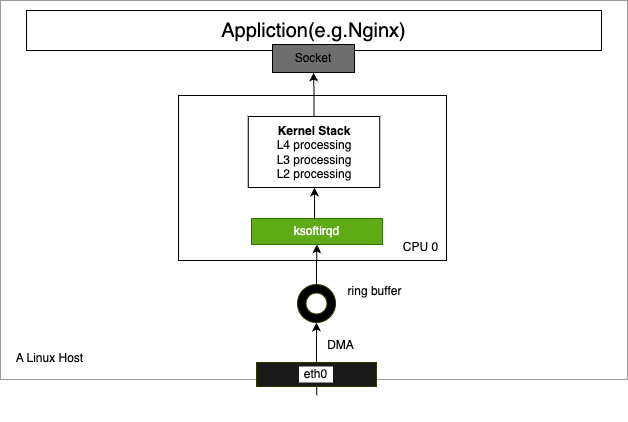
- 网卡收包触发硬中断
数据从网线进入网卡,通过DMA写到ringbuffer,然后就该内核来收包了。由于硬中断期间可能会导致事件丢失,所以在硬中断处理期间不能有耗时操作,只是完成了将数据包放入EQ(Event Queue),之后执行napi_schedule()调度NAPI去处理。在napi_schedule()中,会调用__raise_softirq_irqoff()触发一个NET_RX_SOFTIRQ类型软中断,并触发执行软中断处理函数net_rx_action()。NAPI方式结合了轮询和中段两种方式。每次执行到NAPIpoll()方法时,会批量从ringbuffer收包,并且会尽量把所有待收的包都收完。
- 软中断处理
net_rx_action从处理ringbuffer开始,遍历当前CPU队列的NAPI变量队列,依次执行其poll方法,如mlx5e网卡驱动的mlx5e_napi_poll()。在该函数中,会依次处理TX和RX队列,包含XDP程序(Driver模式)也是在这里执行。之后,从ringbuffer中初始化一个struct sk_buff *skb结构体变量,也就是常说的skb数据包。然后调用napi_gro_receive()执行GRO,GRO的功能是对分片的包进行重组然后交给更上层,以提高吞吐。最后,调用netif_receive_skb_list_internal()进入内核协议栈处理。
- 协议栈L2处理
在netif_receive_skb_list_internal()中,会根据是否开启RPS执行不同逻辑。在未开启RPS时,会通过__netif_receive_skb_core完成将数据送到协议栈处理。在该函数中,会依次进行以下操作:(1)处理skb时间戳。(2)执行Generic XDP程序。(3)处理VLAN header。(4)TAP处理,如tcpdump抓包、流量过滤。(5)流量控制TC,包括TC规则和TC BPF程序。(6)Netfilter,处理iptables规则。最后通过skb->dev->rx_handler(&skb)进入L3 ingress处理,如IPv4处理。
- 协议栈L3处理(以IPv4为例)
IP层在函数inet_init中将自身注册到了ptype_base哈希表中。在deliver_skb()中会调用注册的.func方法,对应IPv4的ip_rcv()函数。ip_rcv()中进行了数据合法性验证、统计计数器更新等,在最后会以netfilter hook的方式调用ip_rcv_finish方法。处理结束的时候,调用ip_local_deliver_finish(),通过寻找注册在这个协议上的struct net_protocol变量,将数据包送到协议栈更上层。如TCP协议对应的tcp_v4_rcv、UDP协议对应的udp_v4_rcv。
- 协议栈L4处理(以UDP为例)
在inet_init()中,通过inet_add_protocol()注册了udp_protocol,其中.handler方法指向了udp_rcv函数。这是从IP层进入UDP层的入口。在该函数中,调用了__udp4_lib_rcv()接收UDP报文。在__udp4_lib_rcv中,首先进行合法性检查,获取UDP头、UDP数据报长度、源地址、目标地址等信息,然后进行一些完整性检测和checksum验证。在IP层中,送到更上面一层协议前,会将一个dst_entry关联到skb,如果对应的dst_entry找到了,并且有对应的socket,udp4_lib_rcv 会将 packet 放到 socket 的接收队列。网络数据通过__skb_queue_tail()进入socket接收队列,并且会在之前进行一些检查和更新计数,并通过sk_filter执行socket BPF程序。
3.网络性能观测方法
3.1 概述
网络性能包括链路上的包转发时延、吞吐量、带宽等指标,也包括主机侧的实时网络状况,传统工具包括:ss、ip、nstat、netstat、sar、nicstat、ethtool、tcpdump等,BPF工具包括:netsize、nettxlat、superping、tcpconnect、tcplife、tcptop、udpconnect、sockstat等,这些工具包含了网络子系统的各个层面,如图所示,可以对系统网络状况进行较为全面的了解,从而进一步去分析可能存在的问题与瓶颈,提升网络性能。
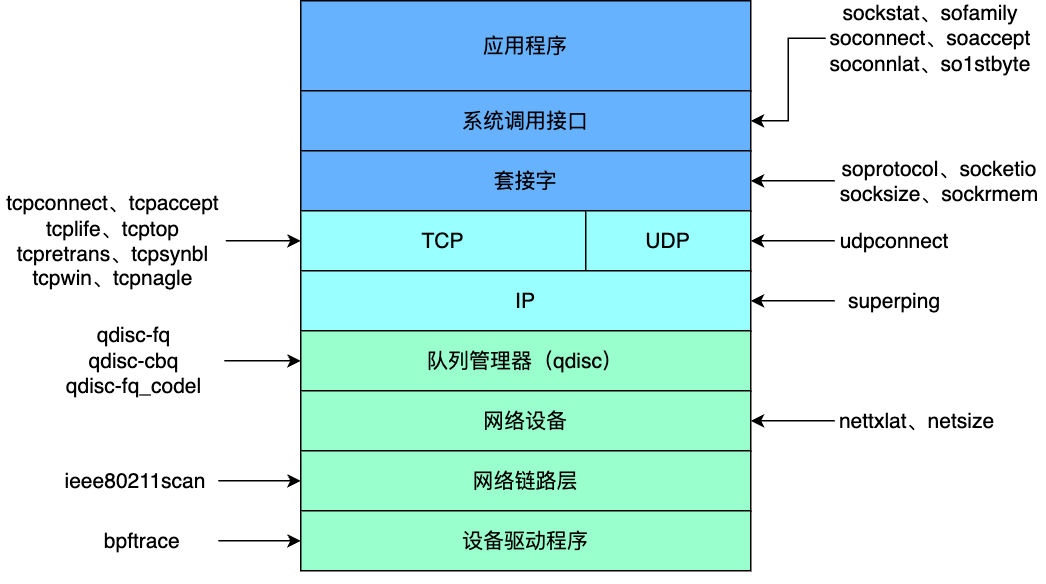
3.2 链路层与网络层
(1) 传统工具
- ethtool
ethtool可以利用-i和-k选项检查网络接口的静态配置信息,也可利用-S选项打印驱动程序统计信息。如图所示。
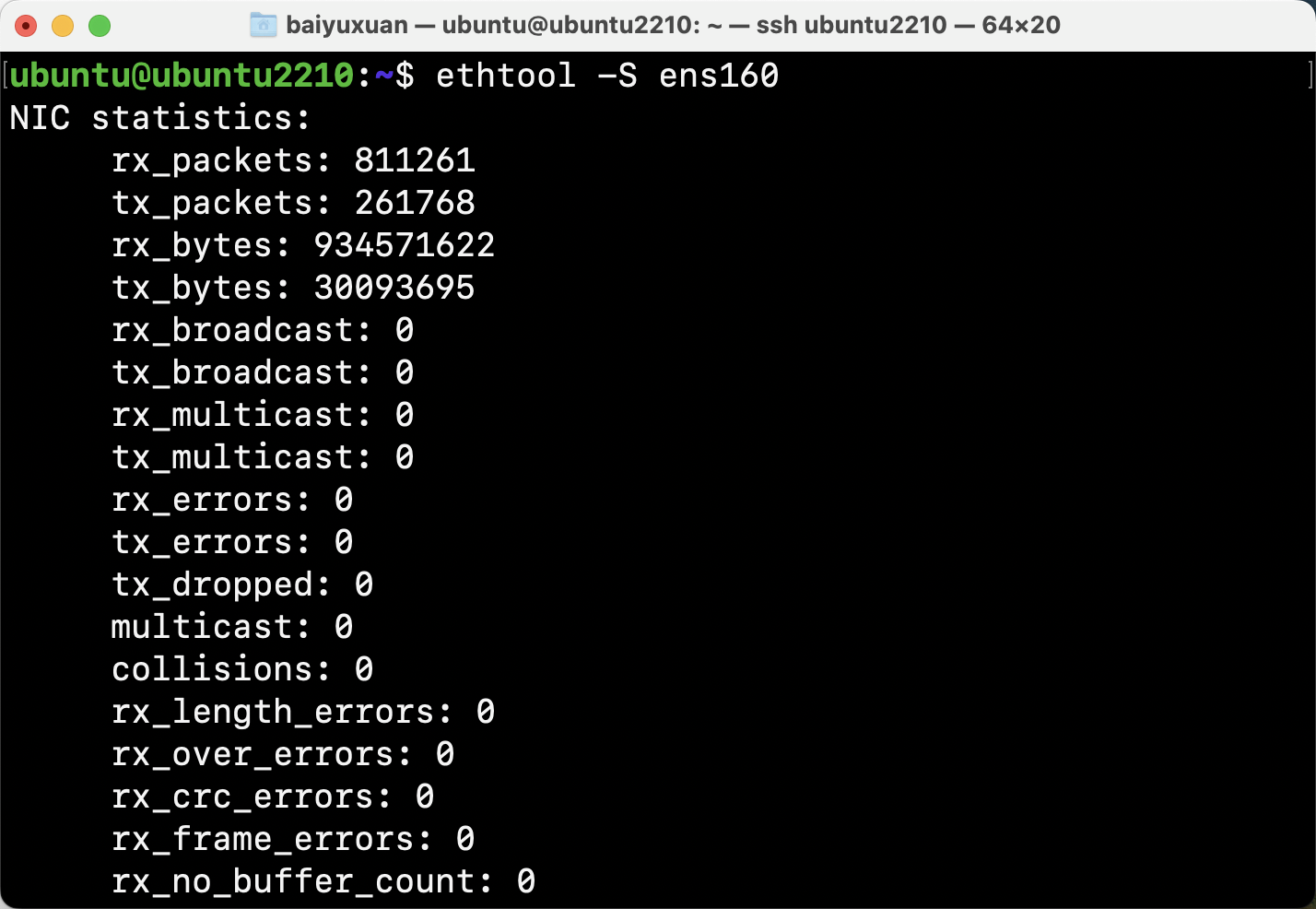
这行命令从内核中的ethtool框架中获取统计信息,大部分网络设备驱动程序都支持该框架。网络设备驱动程序也可定义自己的ethtool指标。
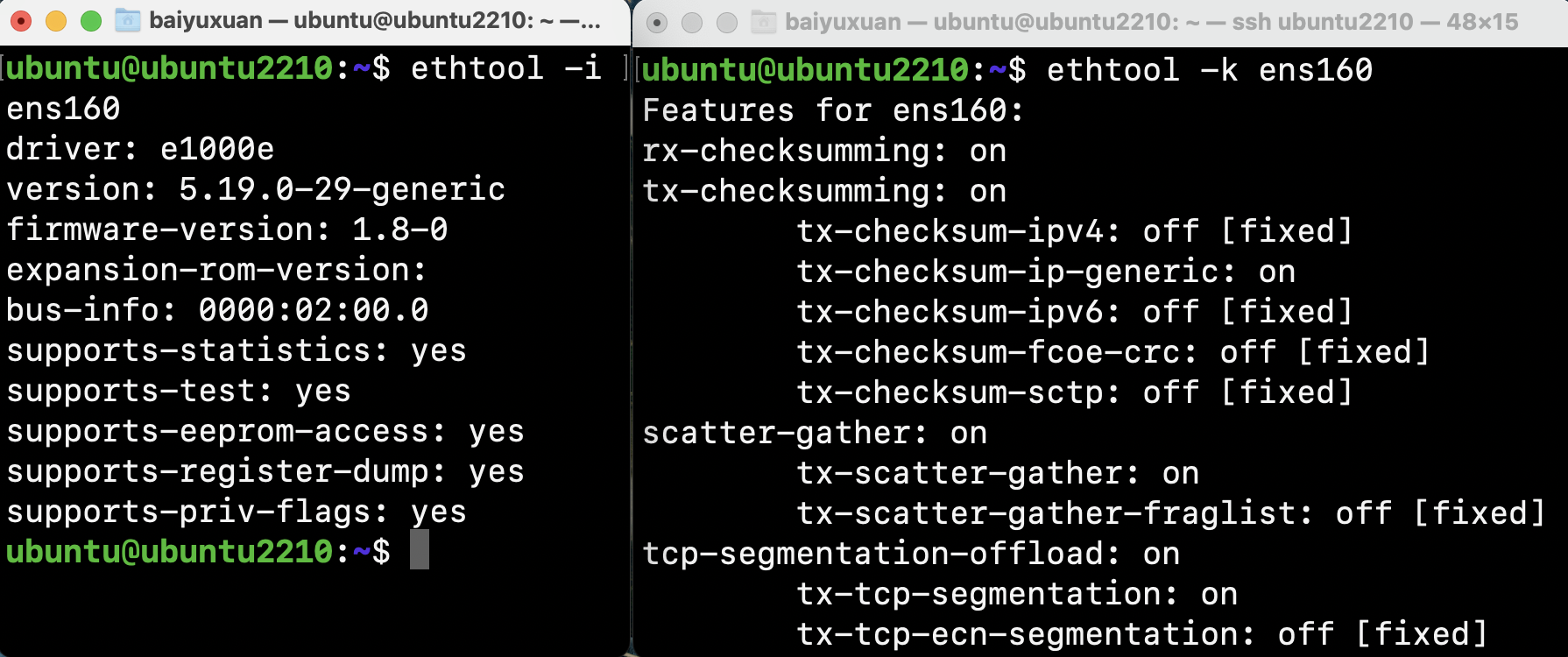
使用-i选项可展示驱动细节信息,使用-k 可展示网络接口的可调节项,如图所示。
- nicstat
nicstat可以打印网络接口的统计信息,如图所示。
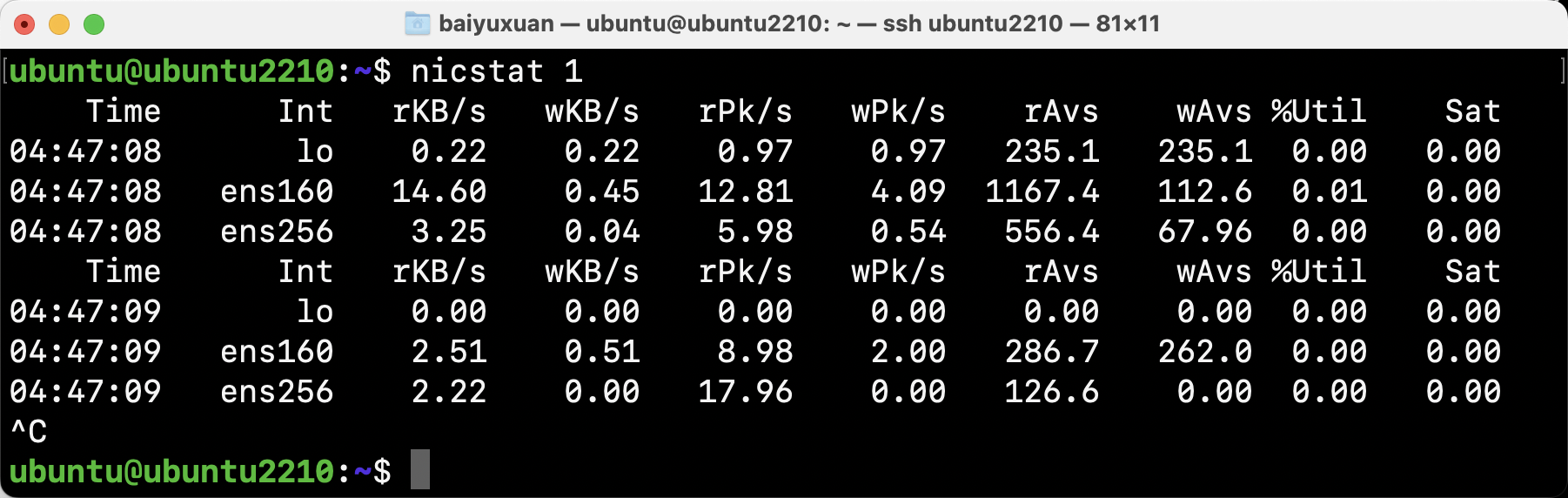
这个输出中包括了一些饱和度统计信息,可以用来识别网络接口的饱和程度。
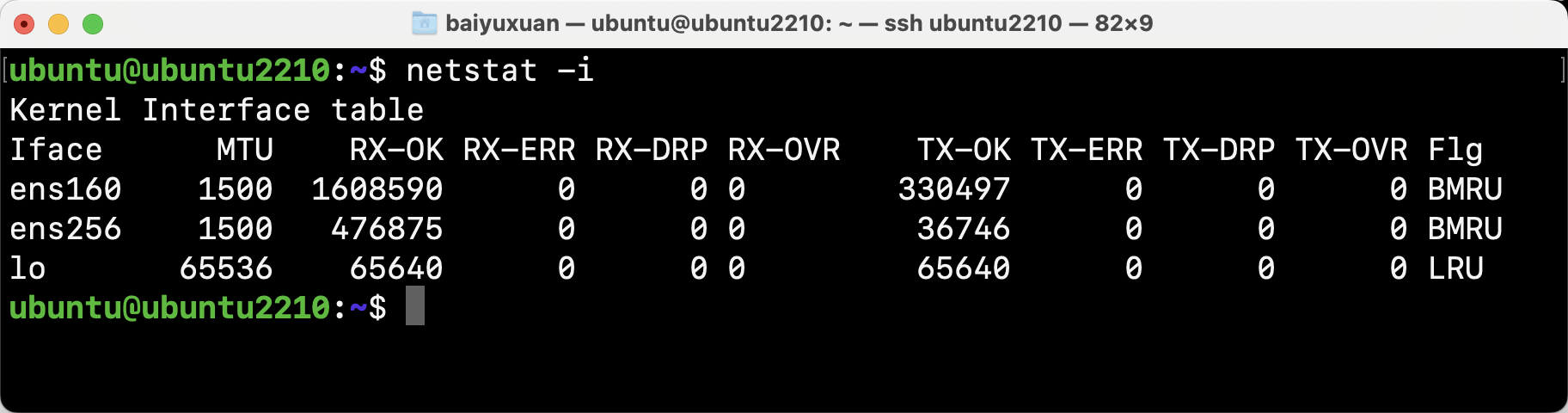
- netstat
netstat是一个用来汇报各种类型的网络统计信息的传统工具,包括以下命令:
| 参数 | 描述 |
|---|---|
| (default) | 列出所有处于打开状态的套接字 |
| -a | 列出所有套接字的信息 |
| -s | 网络软件栈统计信息 |
| -i | 网络接口统计信息 |
| -r | 列出路由表 |
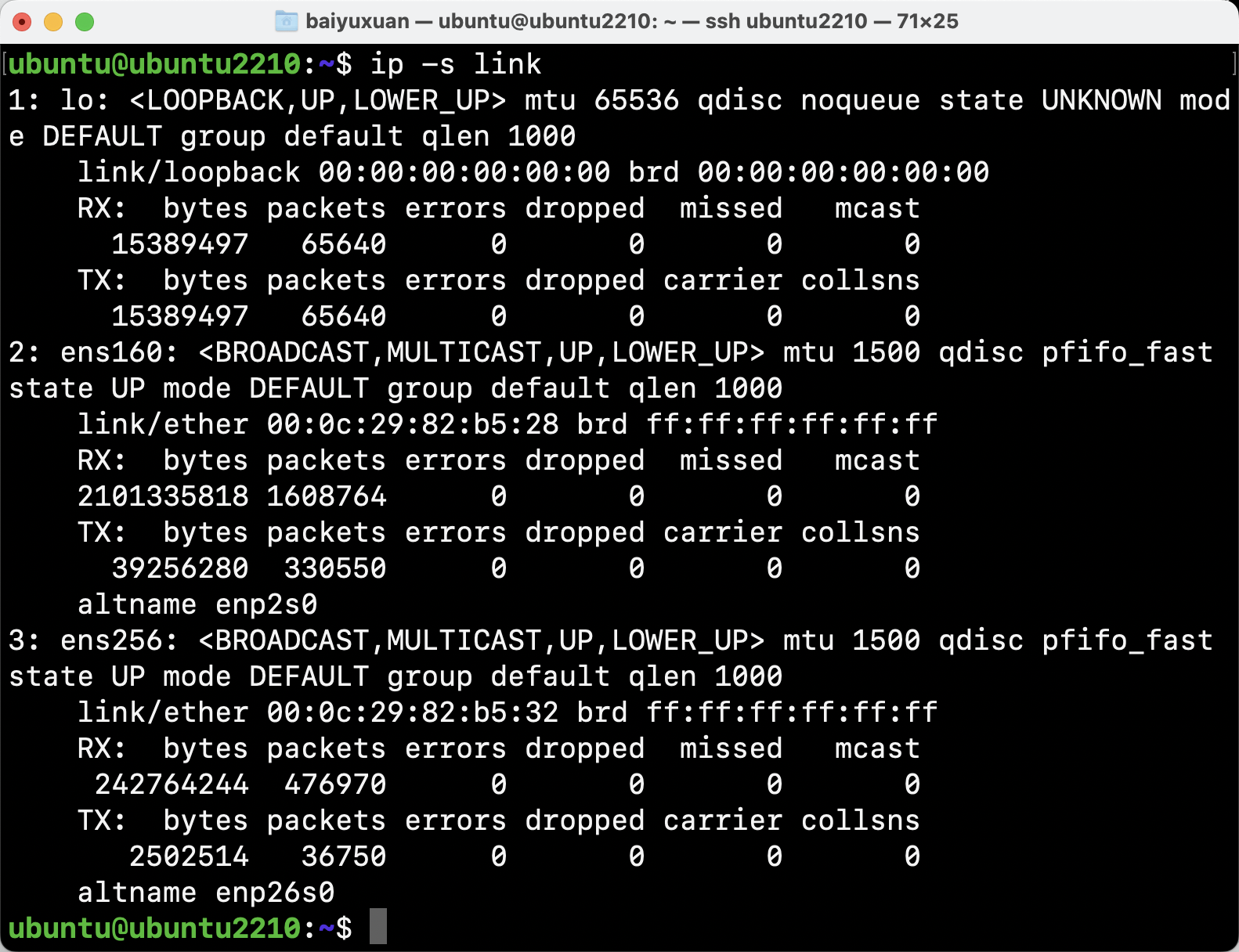
- ip
ip是一个管理路由、网络设备、接口以及隧道的工具,可用来打印各种对象的统计信息,如link、address、route等。如图为使用ip -s link打印link的统计信息。
- sar
系统报表活动工具sar可以打印出各种网络统计信息表。
| 参数 | 说明 |
|---|---|
| -n DEV | 网络接口统计信息 |
| -n EDEV | 网络接口错误统计信息 |
| -n IP,IP6 | IPv4、IPv6数据包统计信息 |
| -n EIP,EIP6 | IPv4、IPv6错误统计信息 |
| -n ICMP,ICMP6 | IPv4、IPv6 ICMP统计信息 |
| -n EICMP,EICMP6 | IPv4、IPv6 ICMP错误统计信息 |
| -n TCP | TCP统计信息 |
| -n ETCP | TCP错误统计信息 |
| -n SOCK,SOCK6 | IPv4、IPv6 套接字用量 |
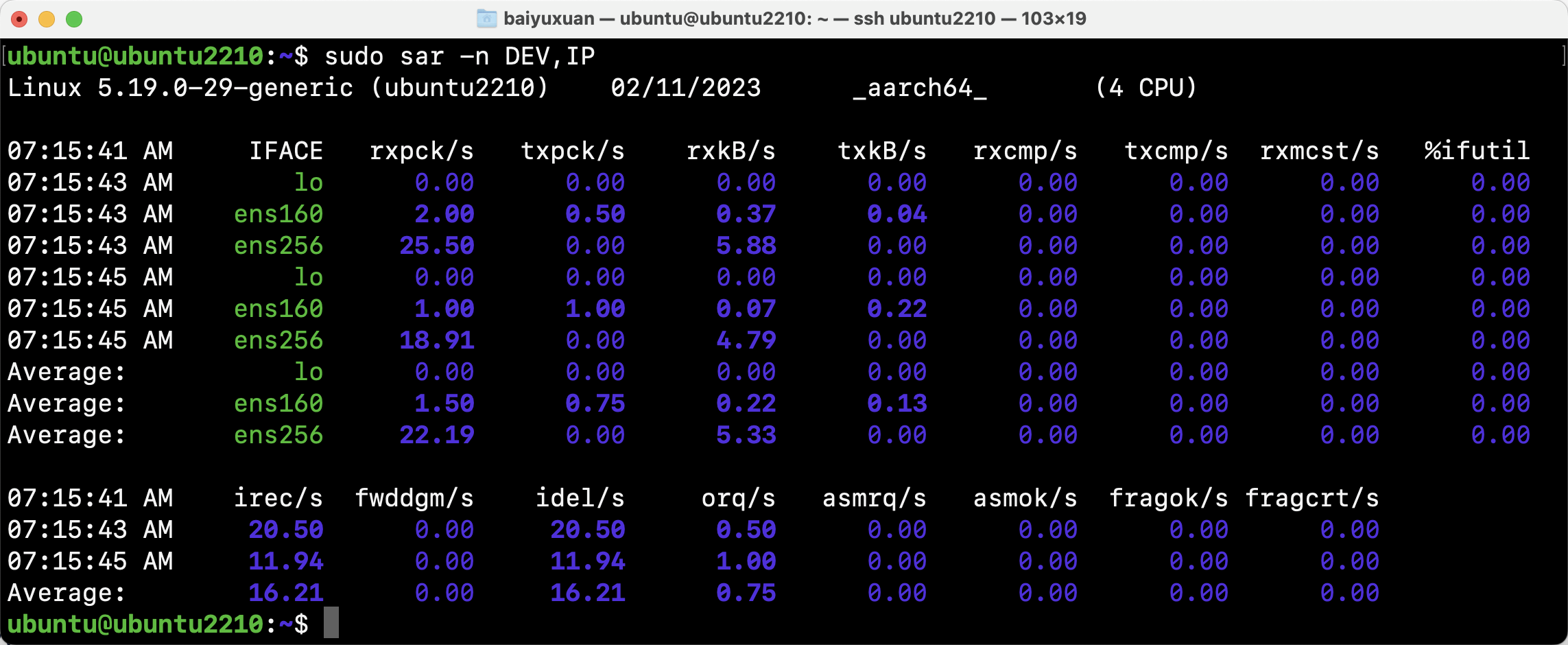
上图为sar -n DEV,IP运行结果,可以看到关于网络设备和IPv4统计信息
(2) BPF工具
netsize从网络设备层展示发送和接收的包的大小,可以同时显示软件分段托管之前和之后的大小(GSO和GRO)。该输出可以用来调查发送之前的碎片化情况。
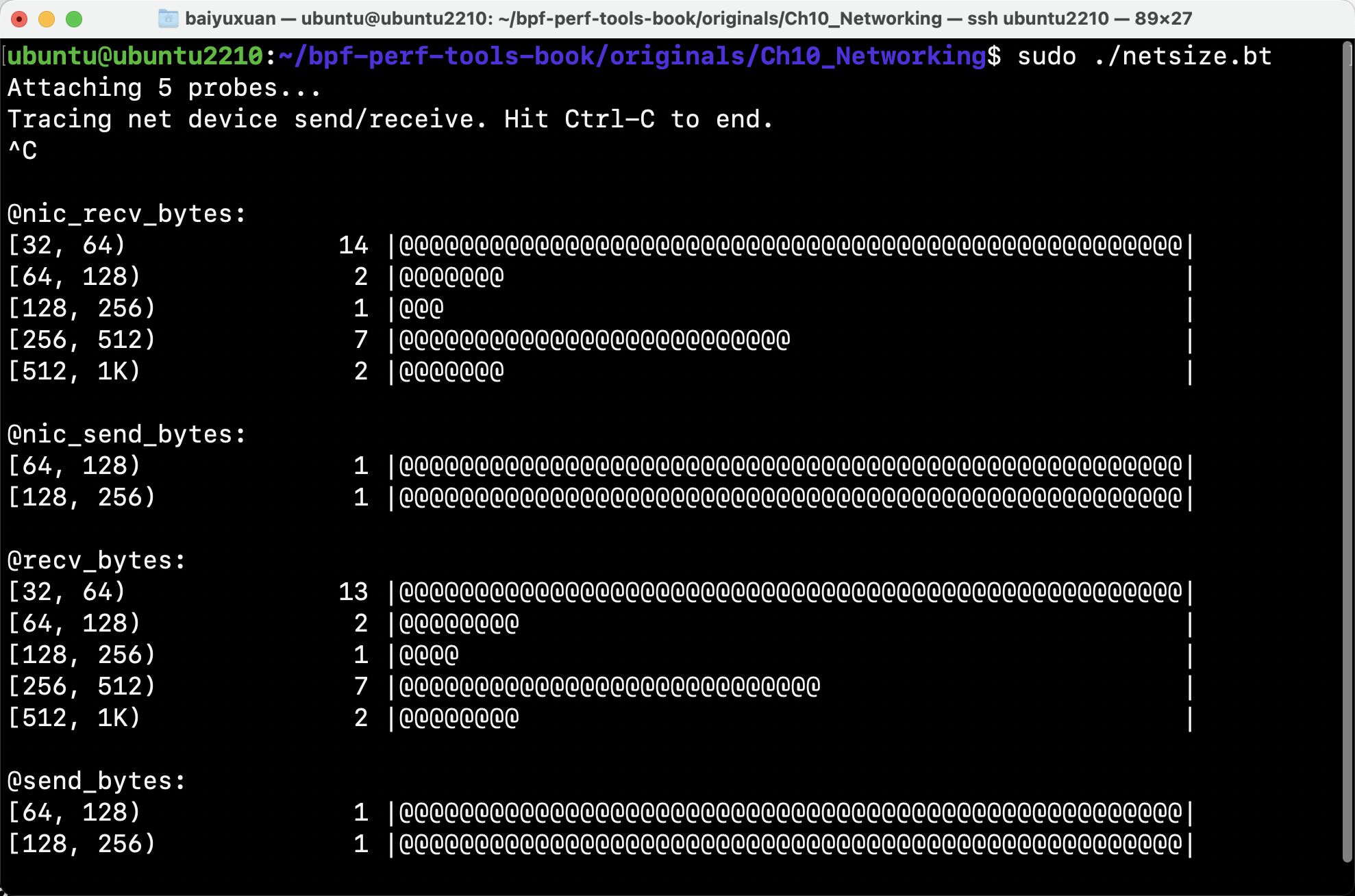
- netqtop
netqtop对指定网络接口的每个队列的传输和接收的数据包进行统计,帮助开发者检查其流量负载是否平衡。 结果显示为一个表格,列有PPS、BPS、平均大小和数据包计数。每隔给定的时间间隔以秒为单位进行打印,如图所示。
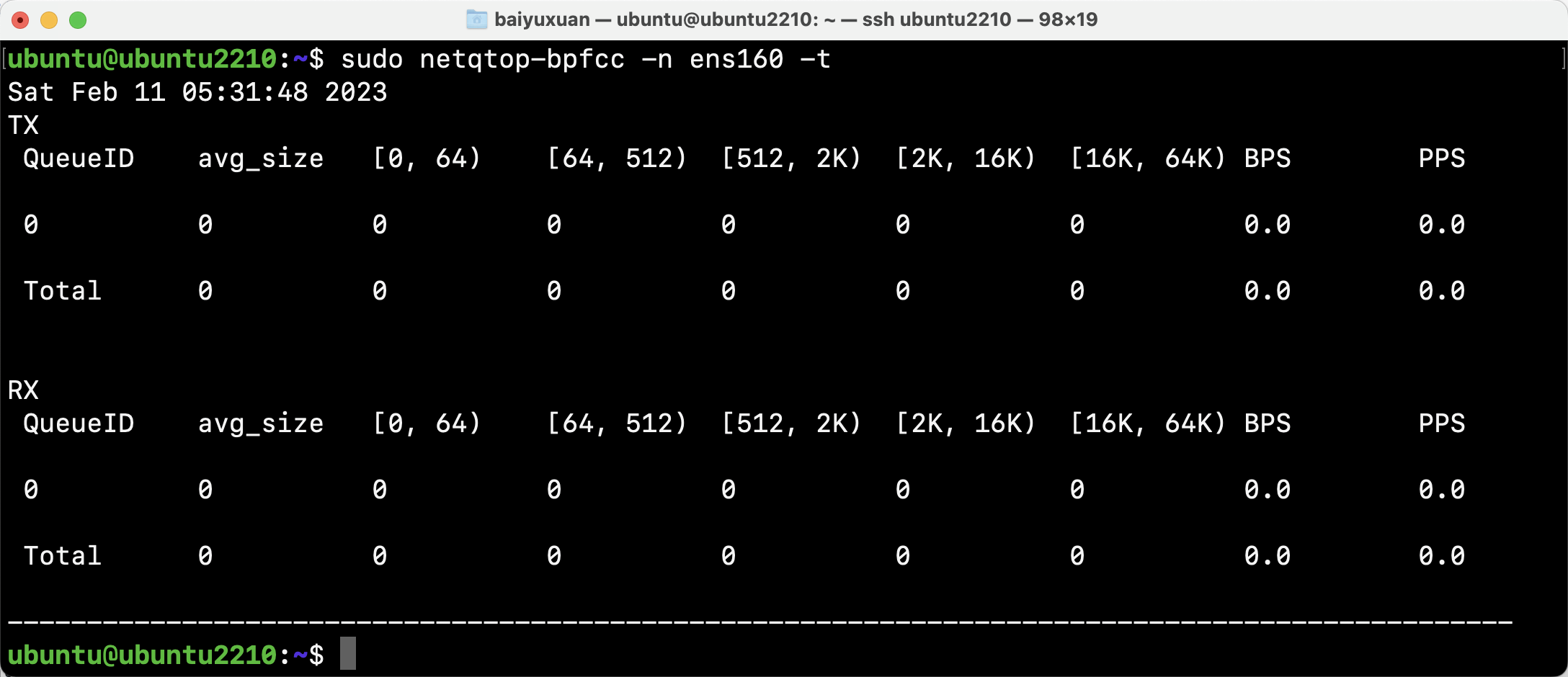
该工具使用net:net_dev_start_xmit和net:netif_receive_skb内核追踪点。 由于它使用tracepoint,该工具只在Linux 4.7以上版本上工作。 netqtop在网络流量大的时候会引入大量的开销。
3.3 传输层
(1) 传统工具
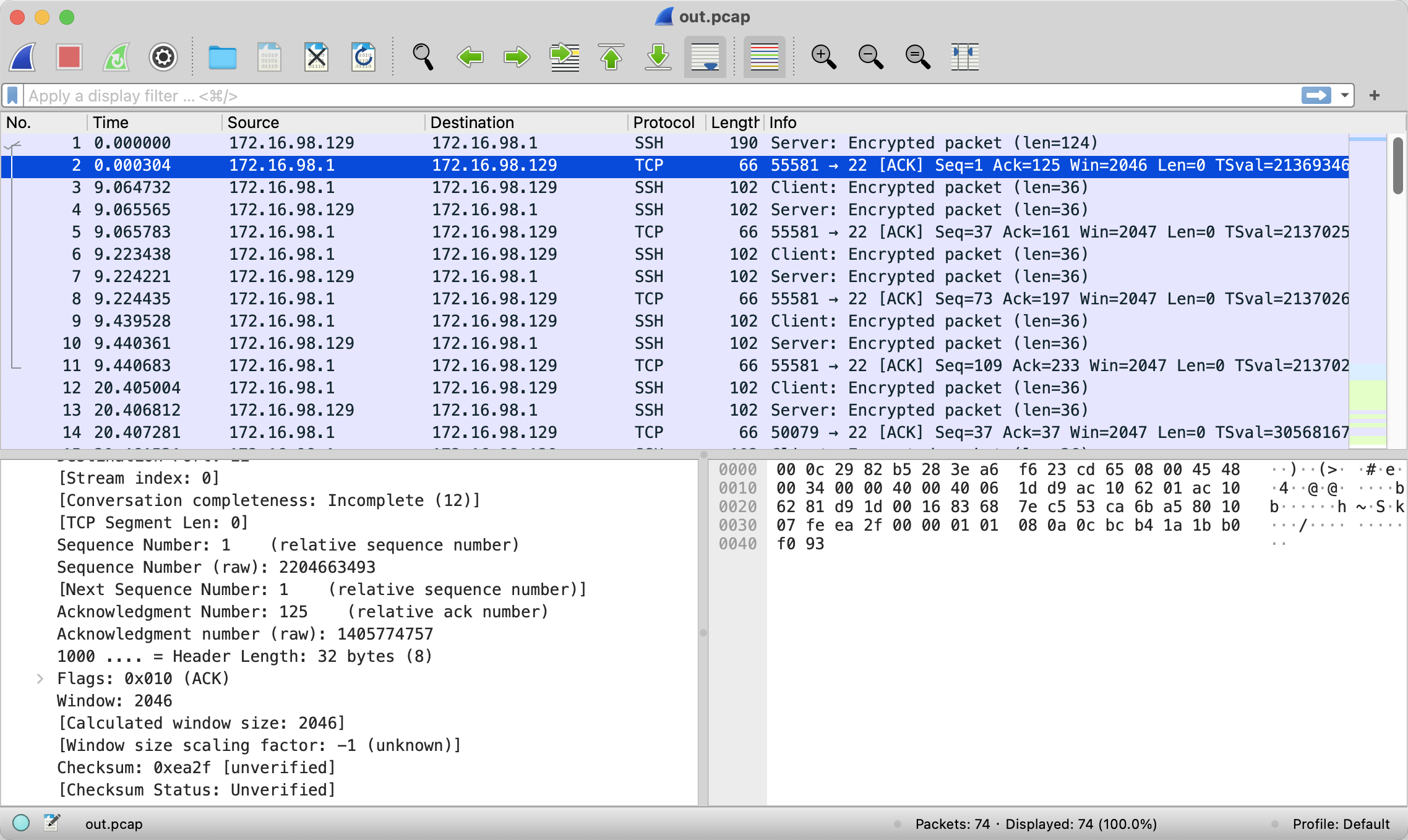
- tcpdump
tcpdump可以用来抓取网络包进行分析。借助Wireshark GUI工具,可以利用tcpdump的输出文件来检查包头、跟踪某个TCP连接、进行包重组以及其他操作,如图所示。
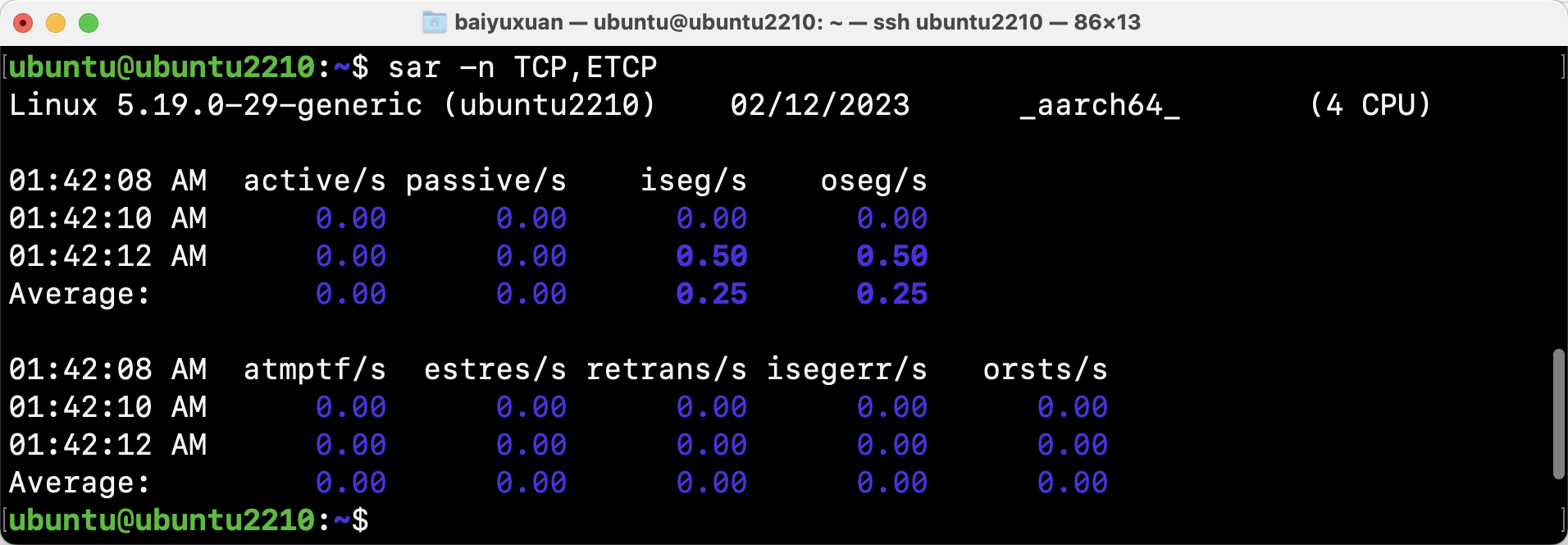
- sar
通过sar获取TCP统计信息sar -n TCP,ETCP
(2) BPF工具
- tcptop
tcptop是一个BCC工具,可以展示使用TCP的进程,如图所示。该工具跟踪TCP发送和接收的代码路径,包括tcp_sendmsg、tcp_cleanup_rbuff,并将数据记录在BPF Map中。通过参数-p可以指定仅跟踪的进程PID。
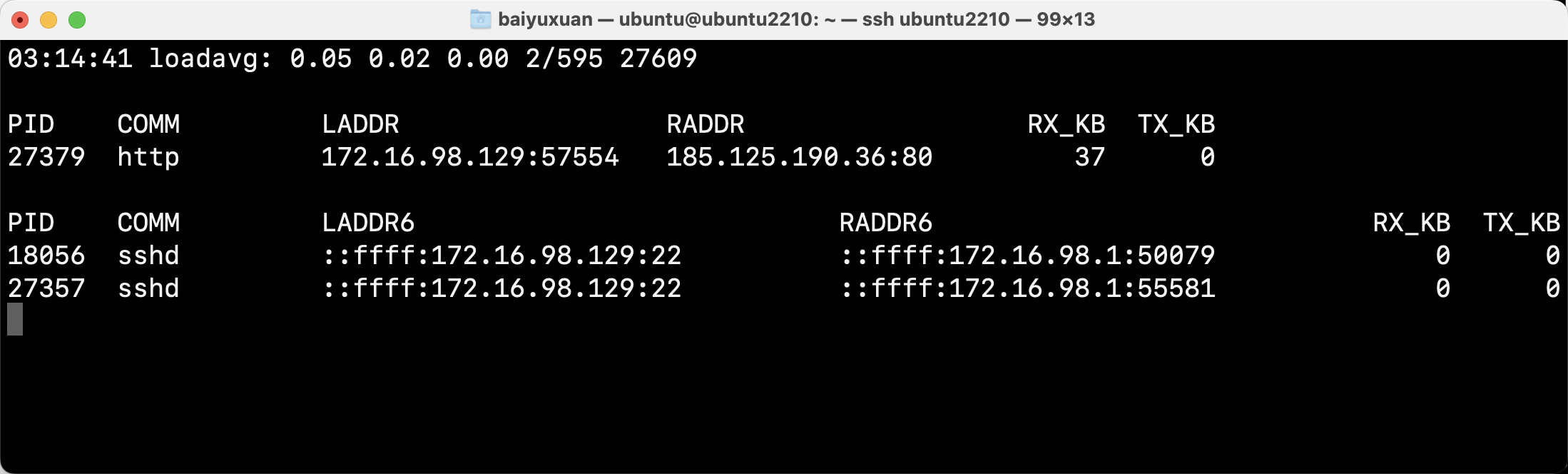
- tcpwin
tcpwin跟踪TCP发送拥塞窗口的尺寸,以及其他的内核参数,以便分析拥塞控制算法的性能,如图所示。
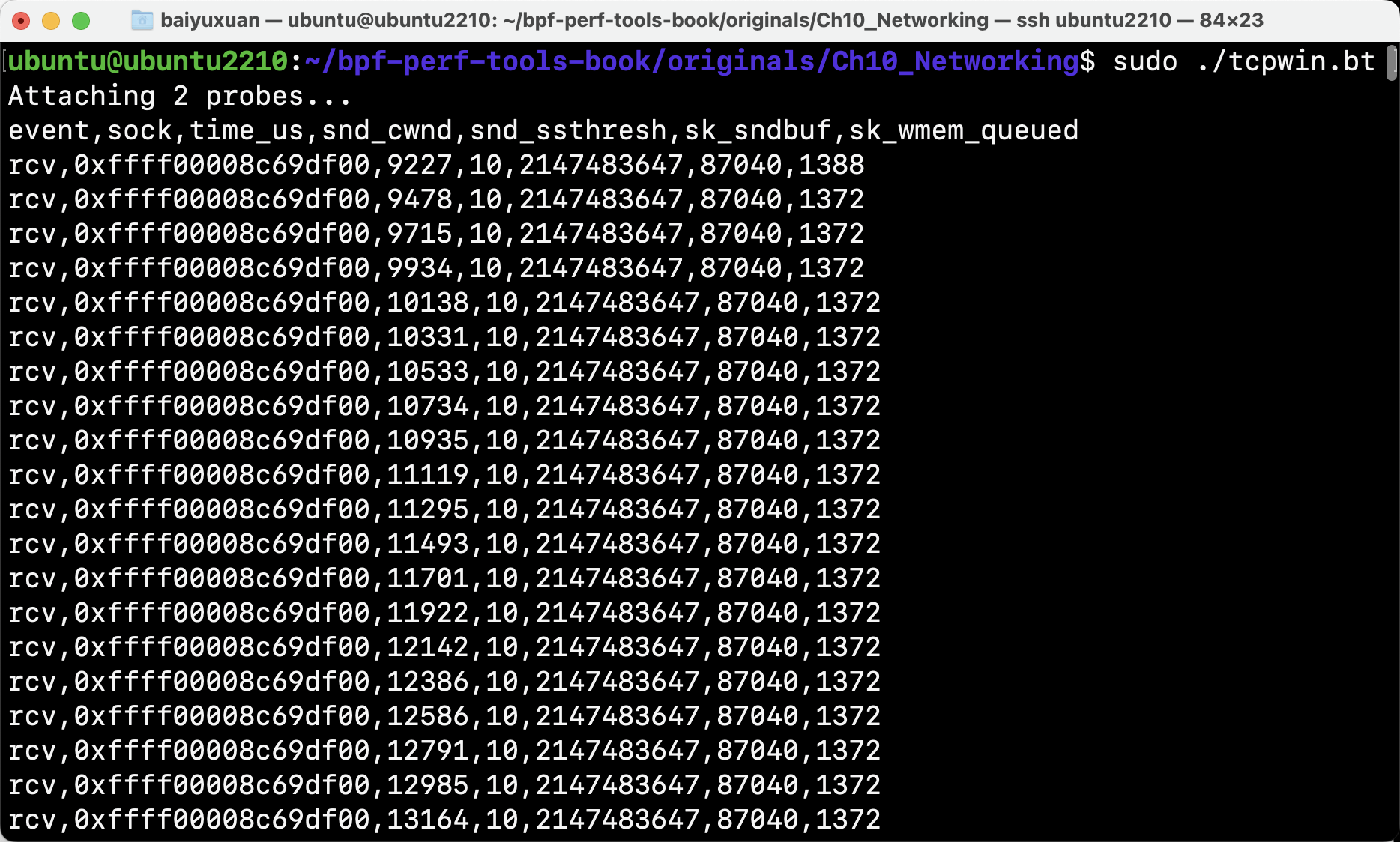
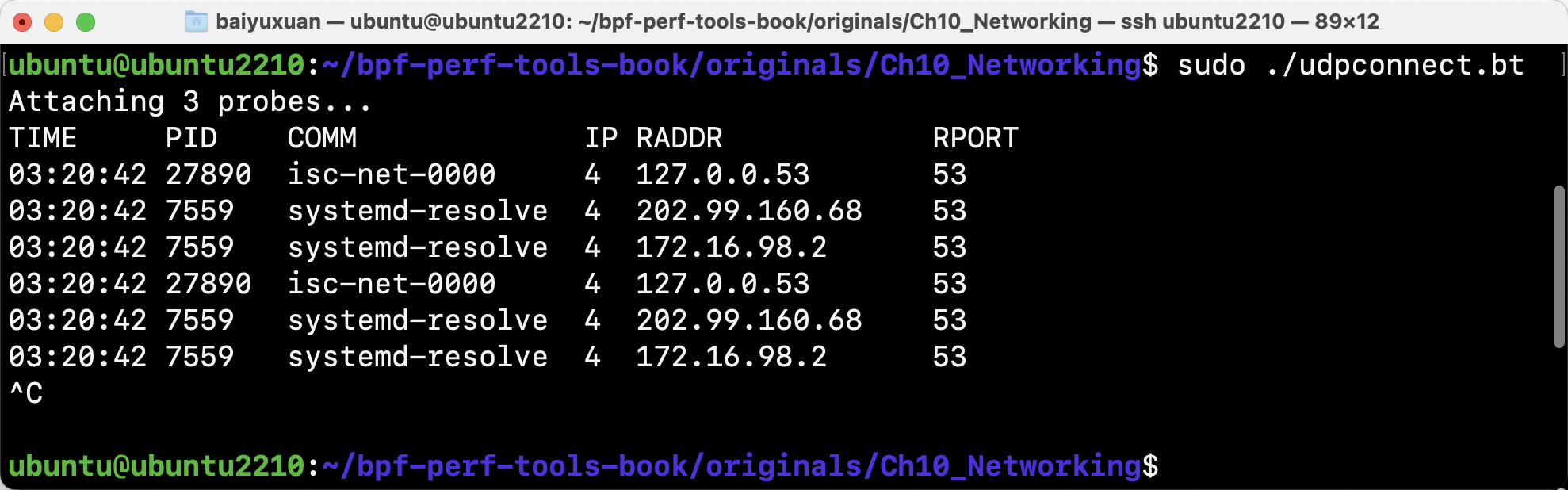
- udpconnect
udpconnect跟踪本机通过connect系统调用发起的UDP连接(不包括无连接的UDP通信),如图所示。该工具跟踪内核中的UDP连接函数,并且由于该函数调用频率较低,所以该工具的额外开销很低。
3.4 套接字
(1) 传统工具
- ss
ss是一个套接字统计工具,可以简要输出当前打开的套接字信息。默认的输出提供了网络套接字的高层信息,可以使用以下选项显示更多信息:
| 参数 | 描述 |
|---|---|
| -a,–all | 显示所有套接字 |
| -m,–memory | 显示套接字内存使用情况 |
| -i,–info | 显示内部TCP信息 |
| -t,–tcp | 仅显示TCP套接字 |
| -u,–udp | 仅显示UDP套接字 |
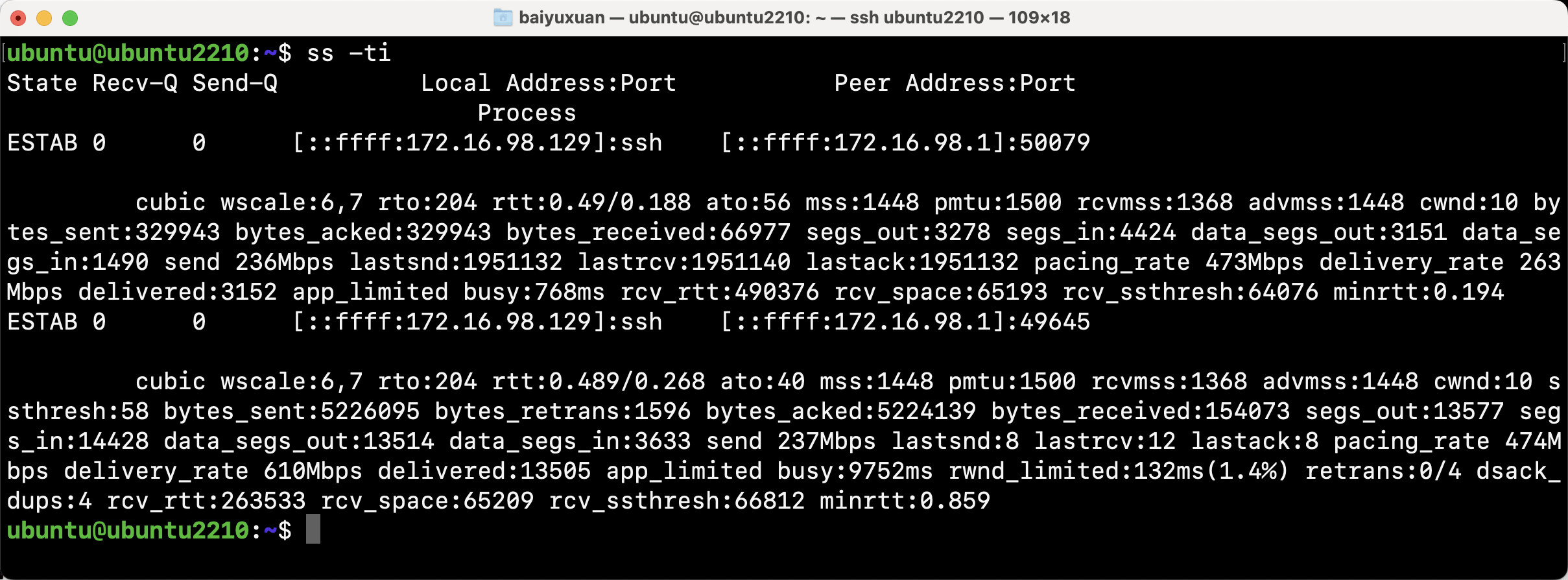
通过-ti参数可以显示更多tcp内部信息,包括以下信息:
| 参数 | 描述 |
|---|---|
| cong_alg | 拥塞算法名称,默认为”cubic” |
| wscale | 窗口放大倍数 |
| rto | TCP重传超时值,毫秒 |
| backoff | 用于指数回退重传 |
| rtt | RTT(平均往返时间) |
| mss | MSS(最大数据分段长度) |
| cwnd | 拥塞窗口大小 |
| pmtu | 路径MTU |
| ssthresh | TCP拥塞窗口慢启动阈值 |
| bytes_acked/bytes_received | ack/rcv的字节数 |
| segs_out/segs_in | 发出和接收的分段数 |
| lastsnd/lastrcv/lastack | 距离最后一个send/rcv/ack的包的时间,毫秒 |
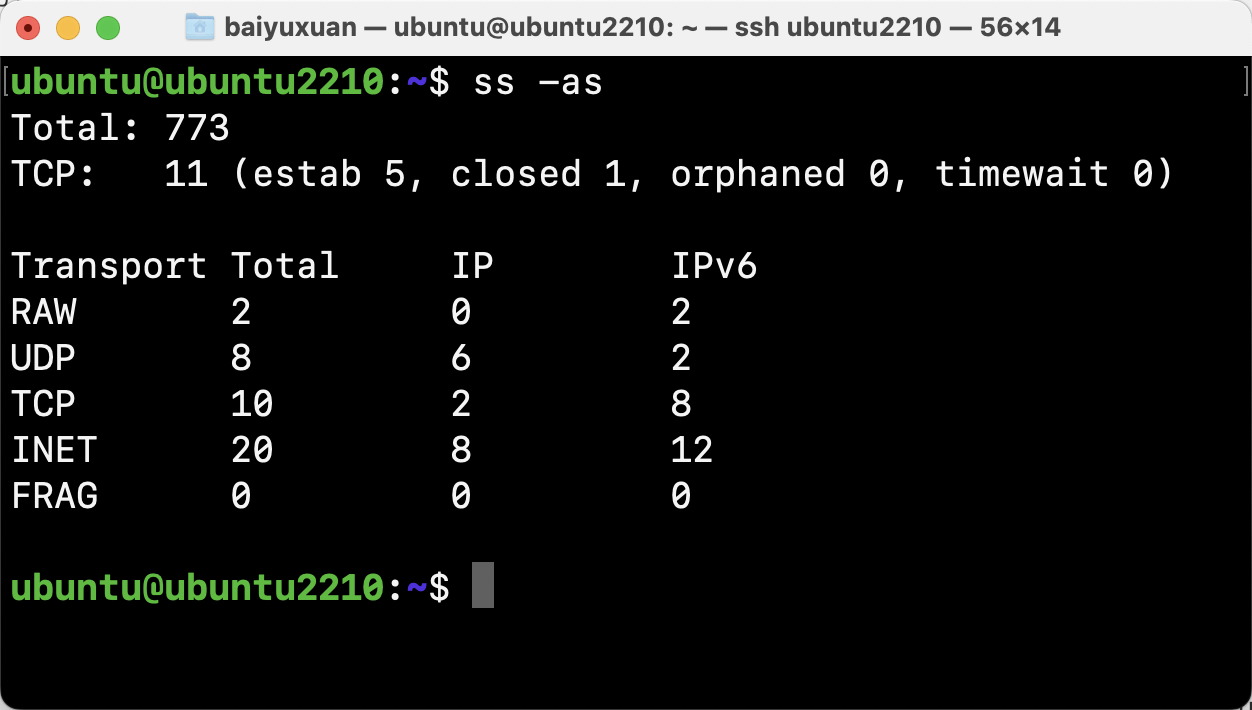
通过-as显示套接字概况
(2) BPF工具
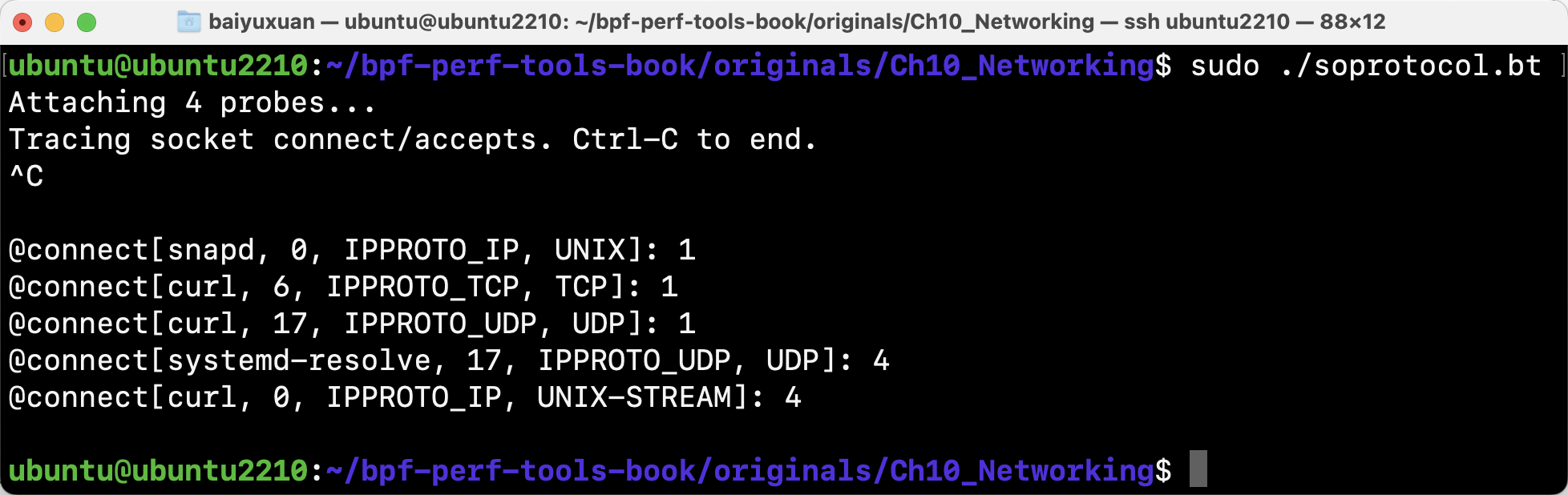
- soprotocol
soprotocol按进程名和传输协议来跟踪新套接字连接的建立,如图所示。
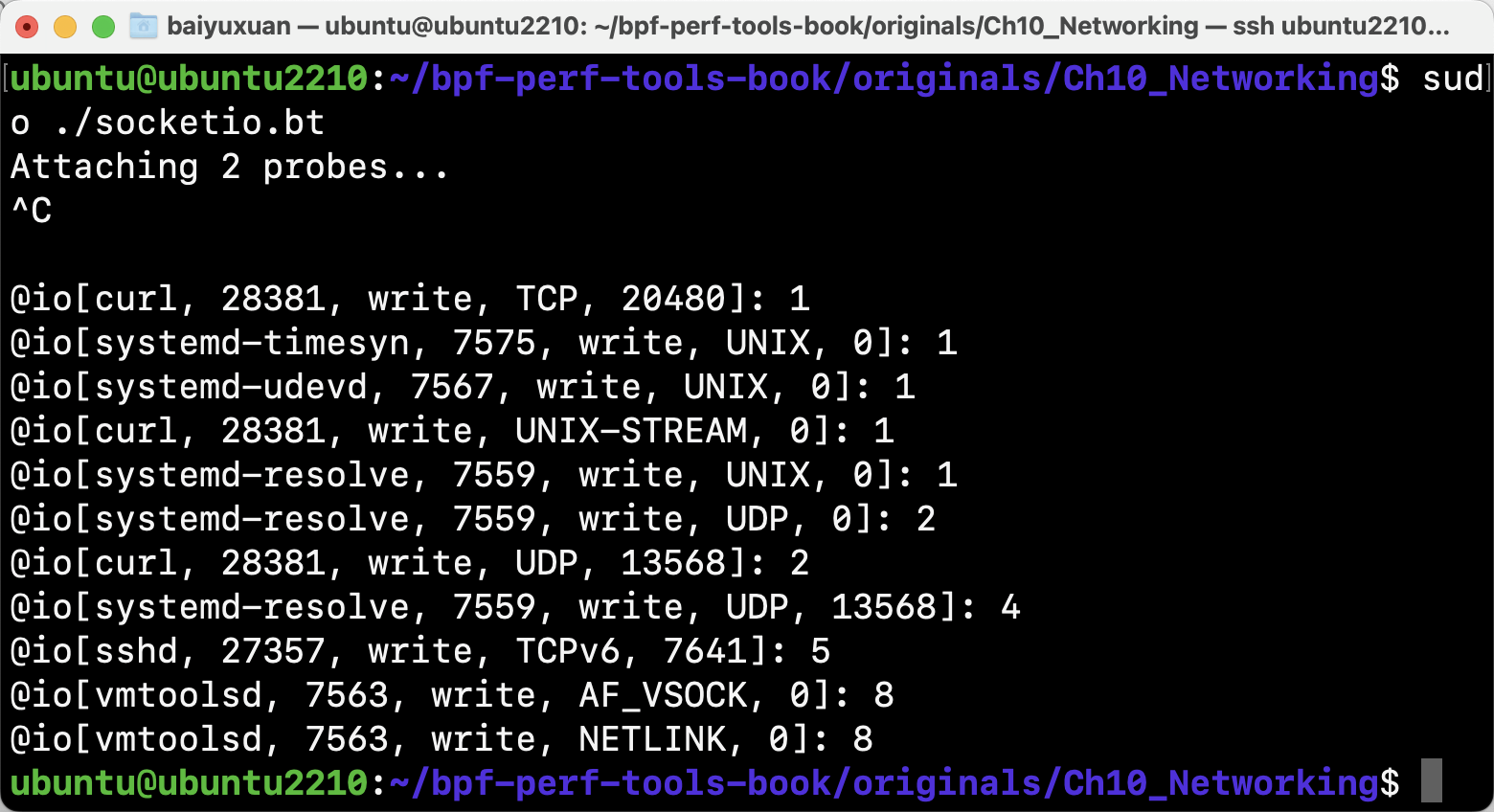
- socketio
socketio按进程、方向、协议和端口来展示套接字的I/O统计信息,如图所示。
4.eBPF网络性能数据提取方法
4.1 概述
nic_throughput是LMP下观测网络性能的eBPF工具,其可以每秒输出指定网卡发送与接收的字节数、包数与包平均大小。(BPS:每秒多少字节 PPS:每秒多少包)
命令行参数:
1 | |
4.2 原理
nic_throughput使用了两个tracepoint跟踪点,分别是:net_dev_start_xmit和netif_receive_skb,分别对应TX和RX路径。
1 | |
通过编写eBPF程序,得到sk_buff结构中字段len的长度,得到包的大小,并且记录次数作为包的数量。
1 | |
在用户态程序,通过读取tx_q和rx_q这两个map,得到单位时间内的总的字节数和包数,与该时间进行除法运算得到BPS和PPS
1 | |
4.3 结果展示与分析
nic_throughput与sar同时进行输出,如图所示。在同一时间点上,对比nic_throughput的数据和sar的数据输出是不同的,尤其是BPS。
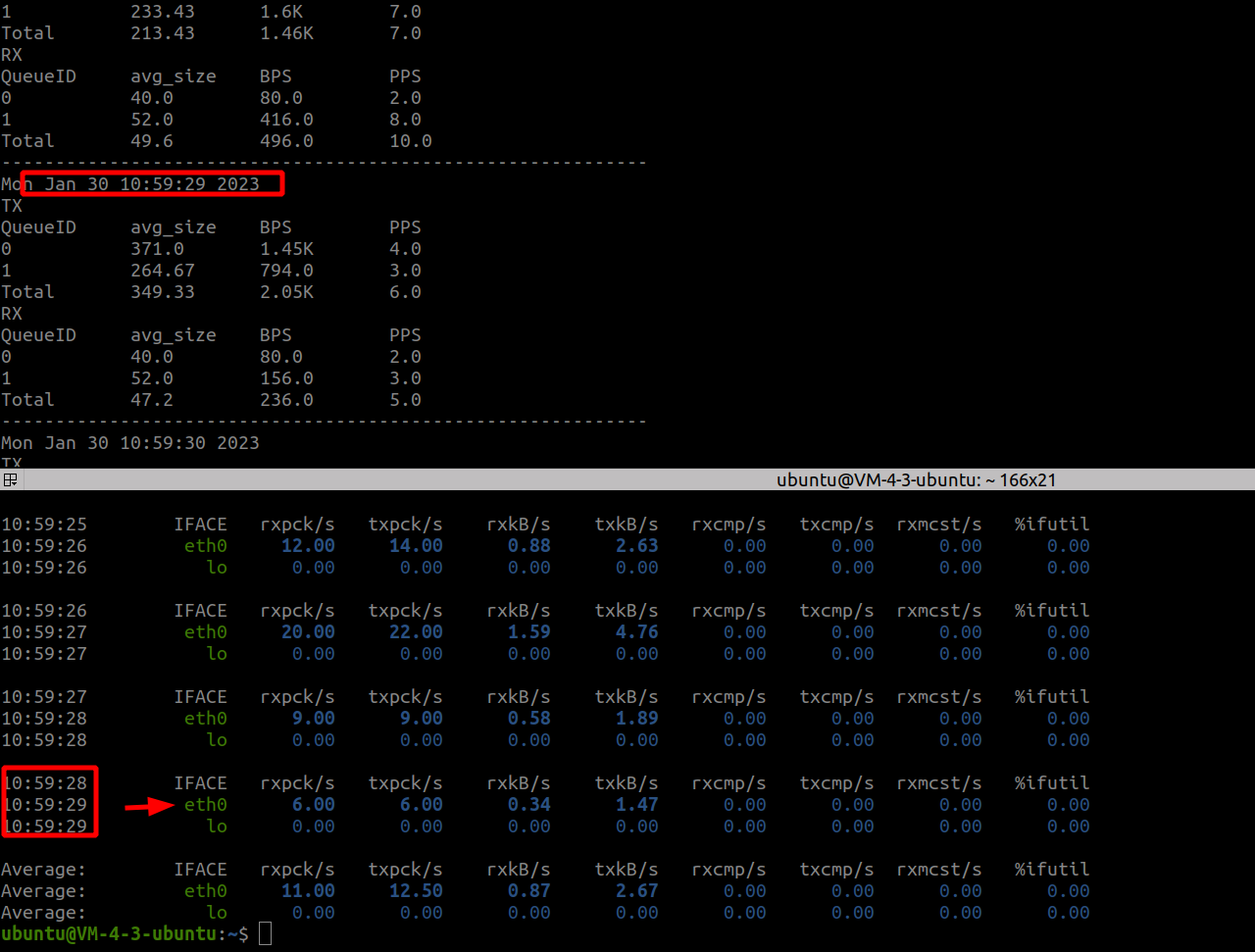
结果的不同是由于数据来源的不同。sar工具的数据来源(DEV参数)是/proc/net/dev,如图所示。

从内核中寻找数据来源
1 | |
这里ndo_get_stats和ndo_get_stats64需要网卡驱动程序实现,以ixgbe网卡驱动为例:
1 | |
可以看出,在ixgbe网卡的最终数据是从ixgbe_ring结构中得到的,而写这个数据的是ixgbe_clean_tx_irq、ixgbe_clean_rx_irq两个函数,而这两个函数正是ixgbe_pollTX和RX队列处理函数。
1 | |
所以,可以看出,二者数据不同的原因是数据源不同。eBPF程序使用tracepoint静态跟踪点统计sk_buff结构中的len字段,而通过sar等传统工具利用的proc文件系统下的net/dev文件数据来源于设备驱动,而这个数据是网卡设备统计的,与tracepoint跟踪点不在一个层面,所以数据值不同。